Since I’ve been playing around with Laravel Envoy, I kept wondering how I could improve the deployment process. For sure it works and I’ve been using it for 6 months or so on a project in production, but having to deal with a physical server has drawbacks I wanted to overcome. For example, the PHP team just released 7.4 packed with cool features I am eager to try. But on a physical server, one has to manually upgrade the PHP version, for each environment and this is a process prone to errors and can lead to different results in different servers. Logistically, the next step was to containerize the application. Because our application is running on an EC2 instance in AWS, I wanted to take advantage of the AWS ecosystem more.
On a high level point of view, this is what I ended up doing: the application is deployed in an ECS cluster running a task that contains a Docker image of the application. This image is stored in ECR. There is an ALB in front of the EC2 instances. The database is stored in RDS. The PHP sessions are stored in a Elasticache memcached server.
This article is dense, because it aims to offer an all-inclusive solution, from your Git repository to the production environment. You do not have to apply everything directly, you can begin by applying some parts and (eventually) do the rest later.
Building the Docker Image
The first step to containerize the application is to effectively make it runnable in a container. Because we will be deploying the container over and over again, it should be stateless. To do this, we use an external service for the database (RDS), as well as for the sessions. In the case of a Laravel application, we can use the Redis cache driver that can be hosted in Elasticache or have the sessions in the database.
It is a good practice to keep the Docker image size as low as possible: it uses less space in the Container Registry, is usually faster to build and to upload. This is why even though official PHP images exist, I chose not to use them and build my own, based on Alpine Linux, a small Linux distribution based on busybox.
My application uses Composer and NPM, so to save some additional space I created a multi stage build, meaning that is uses intermediary images that will not be included in the final image. Thus is it possible to install programs in those images, perform actions and only transfer the output to the final image. For example, I use the official Composer image to download and install the PHP dependencies my application needs and I just copy the output to the next intermediate image, so that my final image does not contain Composer. I do the same for NPM to compile the JavaScript parts of the application, but because I do not need NPM in the final image, it is transferred to the final build.
Without further ado, here is the resulting Dockerfile that I put at the root of my repository.
# Build Stage 1
# Compile Composer dependencies
FROM composer:1.9 AS composer
WORKDIR /var/www
COPY . /var/www
RUN composer install --ignore-platform-reqs --no-interaction --no-dev --prefer-dist --optimize-autoloader
# Build Stage 2
# Compile NPM assets
FROM node:12.13.0-alpine AS build-npm
WORKDIR /var/www
COPY --from=composer /var/www /var/www
RUN npm install --silent --no-progress
RUN npm run prod --silent --no-progress
RUN rm -rf node_modules
# Build Stage 3
# PHP Alpine image, we install Apache on top of it
FROM alpine:3.10
# Concatenated RUN commands
RUN apk add --no-cache zip unzip libzip-dev libpng-dev libxml2-dev libmcrypt-dev curl gnupg apache2 \
php7 php7-apache2 php7-mbstring php7-session php7-json php7-openssl php7-tokenizer php7-pdo php7-pdo_mysql php7-fileinfo php7-ctype \
php7-xmlreader php7-xmlwriter php7-xml php7-simplexml php7-gd php7-bcmath php7-zip php7-dom php7-posix php7-calendar libc6-compat libstdc++ \
&& mkdir -p /run/apache2 \
&& rm -rf /tmp/*
# Apache configuration
COPY apache.conf /etc/apache2/conf.d
# PHP configuration
RUN wget https://elasticache-downloads.s3.amazonaws.com/ClusterClient/PHP-7.3/latest-64bit
RUN tar -zxvf latest-64bit
RUN mv amazon-elasticache-cluster-client.so /usr/lib/php7/modules/
COPY 00_php.ini /etc/php7/conf.d
# Script permission
ADD docker-entrypoint.sh /docker-entrypoint.sh
RUN chmod +x /docker-entrypoint.sh
# Copy files from NPM
WORKDIR /var/www
COPY --from=build-npm /var/www /var/www
# Run script
EXPOSE 80
ENTRYPOINT ["/docker-entrypoint.sh"]
PHP configuration file, called 00_php.ini in the Dockerfile:
upload_max_filesize = 20M
post_max_size = 20M
session.save_handler = memcached
session.save_path = "your-endpoint.region.cache.amazonaws.com:11211"
extension = amazon-elasticache-cluster-client.so
It is setting the upload file size and telling PHP to use Elasticache to store the sessions. You can create a new cluster by going to ElastiCache – Memcached – Create. For a typical PHP application, a small cluster should be enough (cache.t3.micro or cache.t3.small). Then, replace the session.save_path in 00_php.ini by your endpoint.
Apache configuration file, called apache.conf in the Dockerfile:
DocumentRoot /var/www/public
LoadModule rewrite_module modules/mod_rewrite.so
LoadModule session_module modules/mod_session.so
<Directory "/var/www/public">
Options -Indexes +FollowSymLinks
AllowOverride All
Require all granted
</Directory>
ServerTokens Prod
ServerSignature Off
It is setting the document root to the public folder of our Laravel application, enabling the rewrite and sessions module as well as disabling the indexes as well as the tokens that would leak the Apache version.
Finally, the docker-entrypoint.sh executed when the container is launched caches the routes and the configuration of the Laravel application, setting the permissions to Alpine’s Apache’s user running the database migration, running a queue worker in the background and finally running Apache in the background.
#!/bin/sh
# Cache
php artisan route:cache --quiet
php artisan config:cache --quiet
# Permissions
# On Alpine Apache's user and groups are apache
chown -R apache:apache /var/www
chgrp -R apache /var/www/bootstrap/cache
chmod -R ug+rwx /var/www/bootstrap/cache
# Migrations
php artisan migrate --force
# Queue worker
php artisan queue:work --daemon &
# Launch the httpd in foreground
rm -rf /run/apache2/* || true && /usr/sbin/httpd -DFOREGROUND
As you can see, the Dockerfile does the following:
- Installing the Composer dependencies during a first stage
- Installing the NPM dependencies and building the assets (CSS and JavaScript) in a second stage
- Installing Apache, PHP and the necessary packages in the final Alpine image that will be run in production. We use two configuration files to modify the PHP and Apache settings as described above.
Next, we will assume that you already have Docker installed. Simply build the docker image with the following command:
docker build -f Dockerfile -t image-name:tag .
Sending the Image to the Docker Registry
Once the image is built, we need to store it somewhere so that the production servers can retrieve it from there.
Because our image is ready to be run, it contains sensitive data such as production passwords. Thus, it must be stored somewhere safe.
Amazon’s Docker registry, ECR, is interesting in the case of the AWS infrastructure we are building: it integrates seamlessly with ECS (more on that later), is entirely private and cheap. AWS free tier gives you 500mb of free storage, and transfers to EC2 instance in the same region are free. First, create your ECR repository in the region you plan to launch your EC2 instances, then tag and push the image you just built with:
docker tag image-name:tag ECR_REPOSITORY_URL:tag
docker push ECR_REPOSITORY_URL:tag
Of course, you have to replace ECR_REPOSITORY_URL with the one AWS assigned you. It should look like:
000000000000.dkr.ecr.region.amazonaws.com/repository-name
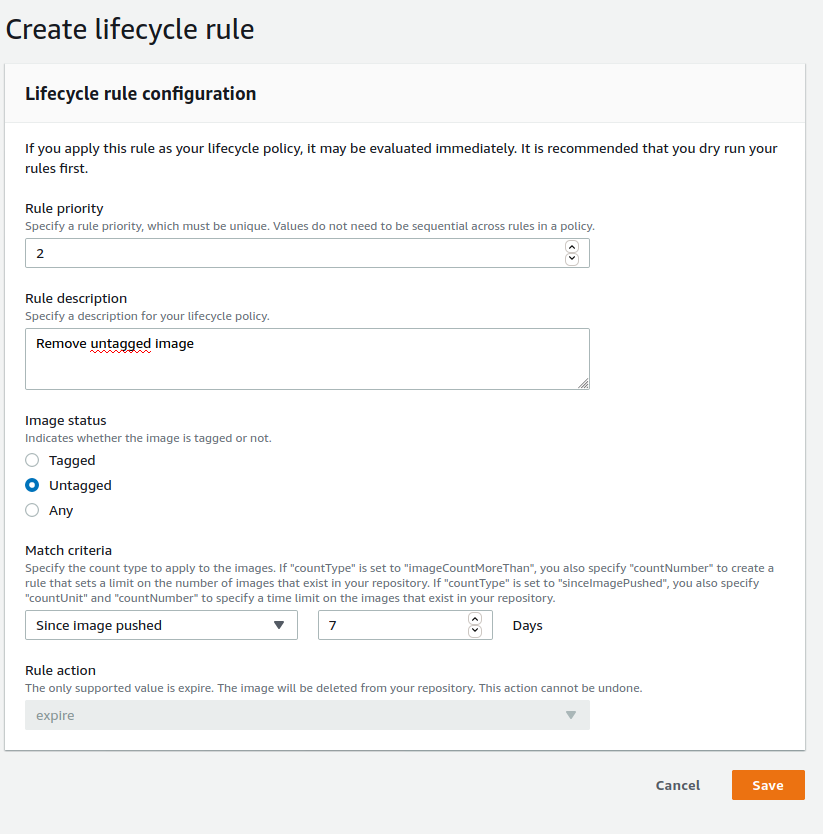
Next, I would advise you to create a lifecycle policy for the images. Because we will use the same tag whenever we want to deploy the application, telling ECS to fetch the latest tag, without a lifecycle policy, images would pile up in an “untagged” state in ECR. To avoid this, I created a lifecycle policy that only keeps untagged images sent less than a week ago.
Go to ECR, make sure you are located in the region you created the repository, enter the repository and click on Lifecycle Policy on the left. Then click on Create rule and fill as shown in the next image:
 ## Creating the Load Balancer
## Creating the Load Balancer
Next, we will create the load balancer. We need one because it will be responsible for checking the containers’ health and redirecting the traffic from the old container to the new one without downtime during a deployment.
Create an Application Load Balancer (ALB). Create two listeners for HTTP and HTTPS traffic.
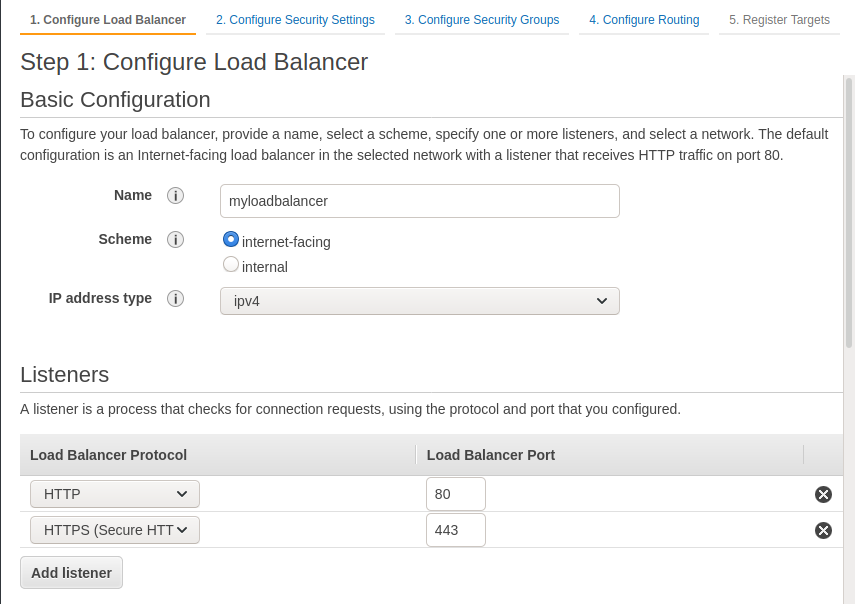 In step 2, you can let Amazon create an SSL certificate or import your own. During Step 3, create a Security Group that you can call web. It will open the ports 80 and 443 for HTTP and HTTPS. This is all we need to expose to the world for the load balancer.
In step 2, you can let Amazon create an SSL certificate or import your own. During Step 3, create a Security Group that you can call web. It will open the ports 80 and 443 for HTTP and HTTPS. This is all we need to expose to the world for the load balancer.
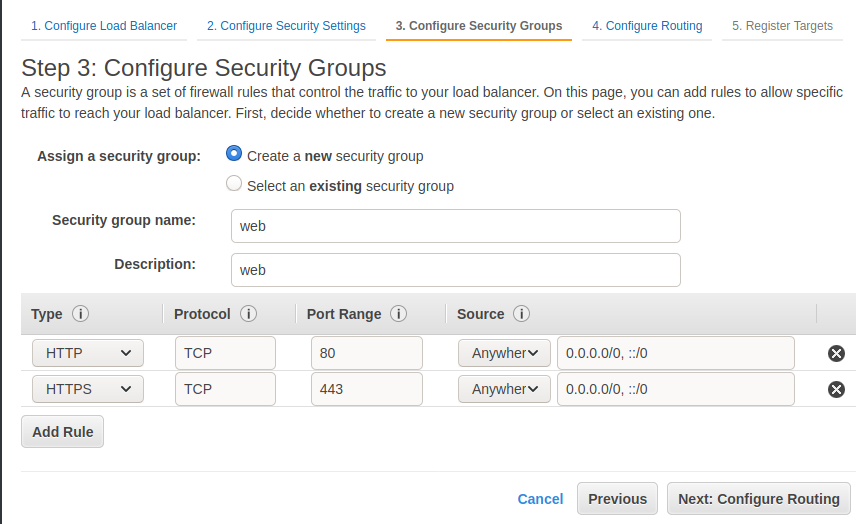 During step 4, you can create a target group as shown below or do it later from ECS.
During step 4, you can create a target group as shown below or do it later from ECS.
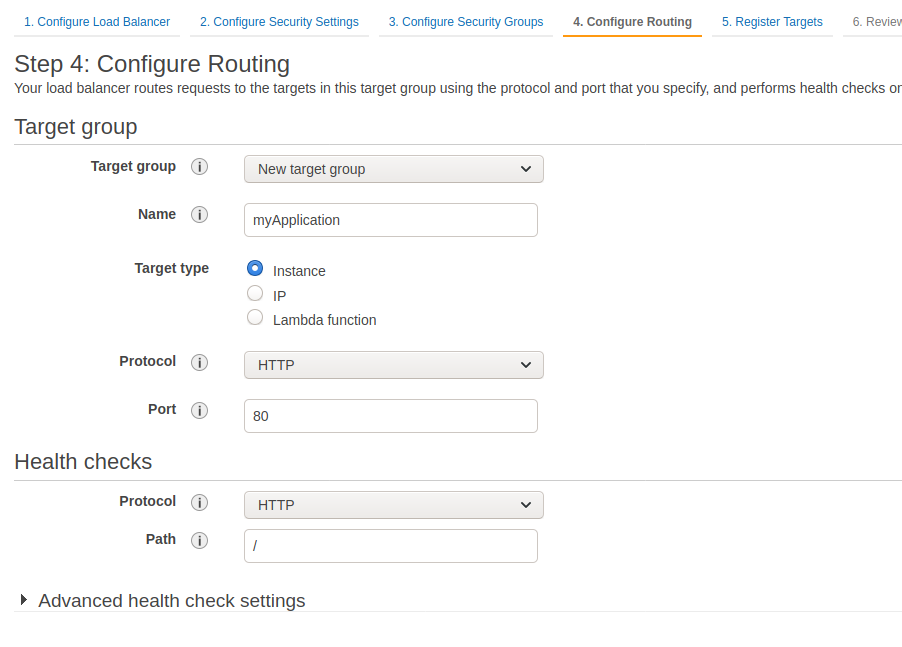 Make sure the health check parameters you chose are valid for your application, ie the path you chose always return a 200 code regardless of the authentication, URL, etc. You can safely ignore step 5 for now. Then, we will create a new security group to allow our IP on the instances’ port 22 to be able to SSH to them. We will also allow all incoming traffic coming from itself, so it should look like this:
Make sure the health check parameters you chose are valid for your application, ie the path you chose always return a 200 code regardless of the authentication, URL, etc. You can safely ignore step 5 for now. Then, we will create a new security group to allow our IP on the instances’ port 22 to be able to SSH to them. We will also allow all incoming traffic coming from itself, so it should look like this:
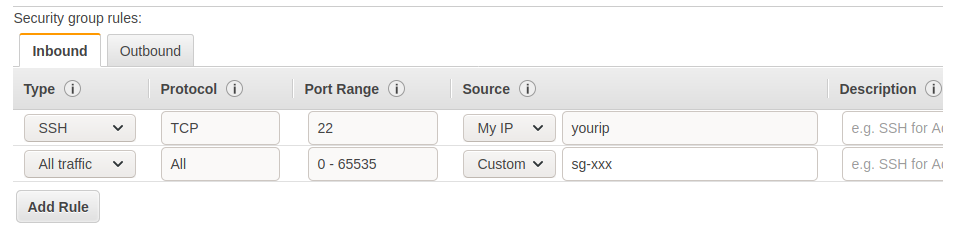 You will have replaced sg-xxx with the newly created security group ID. All the outbound traffic should be allowed. Next, assign the default security group to the newly created load balancer in addition to the “web” security group.
You will have replaced sg-xxx with the newly created security group ID. All the outbound traffic should be allowed. Next, assign the default security group to the newly created load balancer in addition to the “web” security group.
Creating the ECS Cluster
And now, the interesting part! We will create the ECS cluster that will be home to our EC2 instances. ECS clusters are a way to orchestrate the deployment of containers to production and are an alternative to Kubernetes deployment. If you would prefer to use Kubernetes instead, this will not be covered here but you could use EKS instead.
The general idea of ECS is that for each cluster (I have one for production, staging and development environments), there will be services that run tasks. Because my application is really simple (Apache+PHP) I only have one service running one task (2 at most, we will see this later).
When creating the cluster, we are prompted with three choices for cluster template. Fargate allows to run containers in the cloud, without being tied to a specific instance. EC2 Linux runs the container on EC2 instances that one can SSH to.
You should weight the pros and the cons before choosing one over the other. Fargate is more expensive but requires no EC2 administration such as updating the ECS Agent. Fargate also scales up and down easily. On the other side, it is not possible to SSH to the container without modifying the Dockerfile directly. Depending on your application, you may want or have to log into the container to debug for example.
I chose EC2 over Fargate but the rest of the configuration of the cluster should not change much if you chose Fargate. If you do so please let me know how it went in the comments!
On the next screen, choose your cluster name (wisely, it cannot be modified later). You can select On-Demand instances or Spot instances, this can be useful to save money for sandbox environments (staging, dev etc).
Select your EC2 instance type and the number of instances you want to run your application on. In this basic example we only request one instance. Select a key pair if you want to SSH to the instance. Select your VPC, the subnets and the new security group we modified above, allowing SSH and traffic from itself. The cluster will then be created and your EC2 instance has booted and joined the ECS cluster.
Unfortunately, we are not done with the security groups just yet… Because we will use dynamic port mapping on ECS, allowing the same EC2 instance to run more than one container listening on the same port, we have to create a security group to allow this.
Let’s create a new security group opening ports from 32768 through 60999, which is the range located at /proc/sys/net/ipv4/ip_local_port_range and read by Docker >= 1.6.0. In the source, put the security group ID of the “web” security group.
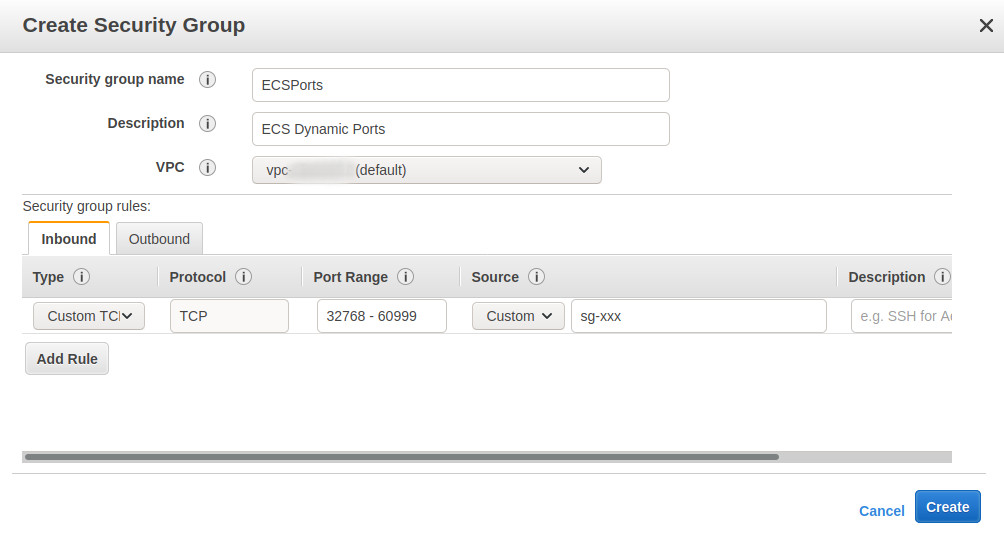 Now, we want to assign both the ECSPorts security group as well as the default one. However, in the AWS Console, we cannot set multiple security groups for an ECS cluster. We have to modify the CloudFormation template directly.
Now, we want to assign both the ECSPorts security group as well as the default one. However, in the AWS Console, we cannot set multiple security groups for an ECS cluster. We have to modify the CloudFormation template directly.
Go to CloudFormation. ECS will have created a stack with a name like EC2ContainerService-ClusterName. Select it. Click on the “Template” tab, the generated template file should be like this. We will add support for multiple security groups to be applied to the EC2 instances. Find the following block:
SecurityGroupId:
Type: String
Description: >
Optional - Specifies the Security Group Id of an existing Security
Group. Leave blank to have a new Security Group created
Default: ''
Add this after:
SecurityGroups:
Type: CommaDelimitedList
Description: The list of SecurityGroupIds in your Virtual Private Cloud (VPC)
Default: ''
Find the following two blocks:
SecurityGroups: [ !If [ CreateNewSecurityGroup, !Ref EcsSecurityGroup, !Ref SecurityGroupId ] ]
SecurityGroups:
- GroupId: !If [ CreateNewSecurityGroup, !Ref EcsSecurityGroup, !Ref SecurityGroupId ]
Replace both with
SecurityGroups: !Ref SecurityGroups
The updated template file should be like this.
Next, update the CloudFormation template with your modified one. To do so, click on the “Update” button in the top right, and upload your file (“Replace current template”, “Upload a template file”). Doing so will create an S3 bucket with the template. In the next page, make sure to fill your two SecurityGroups:
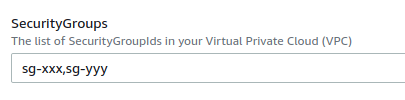 Proceed until you can “Update stack”. When the update is complete, terminate the EC2 instance associated to your ECS cluster so that CloudFormation can spin up a new one applying the new template. The new instance should have the two security groups applied.
Proceed until you can “Update stack”. When the update is complete, terminate the EC2 instance associated to your ECS cluster so that CloudFormation can spin up a new one applying the new template. The new instance should have the two security groups applied.
Finally, we can move on to the actual ECS configuration. We will start by creating a new Task. Go to the Task Definitions tab, and go to Create new Task Definition. Select the EC2 launch type compatibility (or Fargate depending on the cluster type you chose earlier) and proceed to the next step.
Enter the Task Definition Name and move on to the Container Definitions section. This is where we will connect the ECR repository to the ECS task. Select “Add container”.
 Enter the container name and the image. The image will be the URL or the ECR repository, eg:
Enter the container name and the image. The image will be the URL or the ECR repository, eg:
000000000000.dkr.ecr.region.amazonaws.com/repository-name:tag
You are free to use the tag or not, but this is really useful to have different environments from the same repository.
For the port mappings, map the host port 0 to the container port’s 80. This tells ECS that the host port will be dynamic, and point to the port 80 of the container (our web server). Specify the memory limit of the container, if you don’t really know you can put a soft limit of 300-500mb for a web application as AWS recommends. The result should be similar to this:
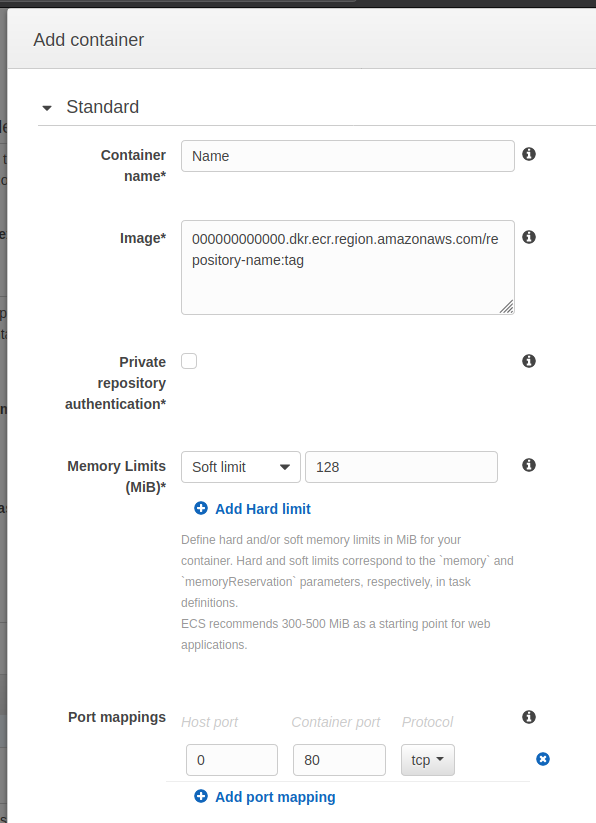 You can now save the container, and save the task definition. Go back to the ECS cluster, and create a new Service.
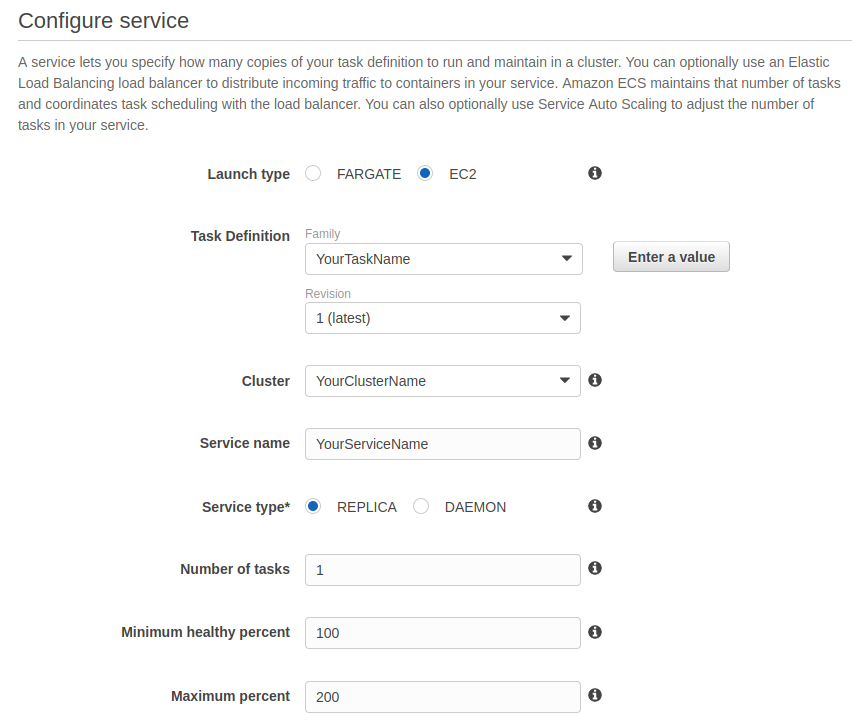
You can now save the container, and save the task definition. Go back to the ECS cluster, and create a new Service.
 Specify the launch type, the cluster, give your service a name use the replica service type and set the number of tasks to 1. Keep the minimum healthy percent to 100 and the maximum to 200. This allows for zero downtime deployment; when a new deployment is triggered, there are two tasks in parallel, the newest one and the current one. When the newest reaches a healthy (ready) state, the load balancer will gradually route the requests to the new one, and remove the old one automatically. You can leave the other parameters as is.
Specify the launch type, the cluster, give your service a name use the replica service type and set the number of tasks to 1. Keep the minimum healthy percent to 100 and the maximum to 200. This allows for zero downtime deployment; when a new deployment is triggered, there are two tasks in parallel, the newest one and the current one. When the newest reaches a healthy (ready) state, the load balancer will gradually route the requests to the new one, and remove the old one automatically. You can leave the other parameters as is.
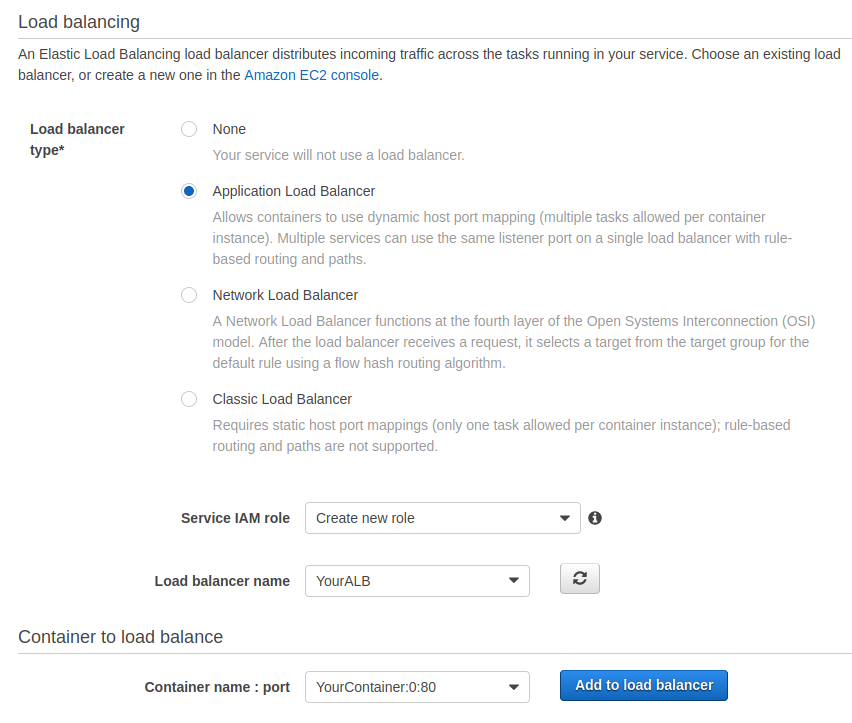
 In the next step, select the Application Load Balancer as load balancer type. Select your load balancer in the dropdown menu. Select your container name in the dropdown menu and click on “Add to load balancer”.
In the next step, select the Application Load Balancer as load balancer type. Select your load balancer in the dropdown menu. Select your container name in the dropdown menu and click on “Add to load balancer”.
 If you created a target group during the creation of the load balancer, simply select this one. If you did not create a target group during the creation of the load balancer, you can then create the target group that the load balancer will forward the traffic to. You can leave the rest unchanged. In the next step, you can configure auto scaling. You can finally create the service after reviewing it.
If you created a target group during the creation of the load balancer, simply select this one. If you did not create a target group during the creation of the load balancer, you can then create the target group that the load balancer will forward the traffic to. You can leave the rest unchanged. In the next step, you can configure auto scaling. You can finally create the service after reviewing it.
Alright, now your service will be created, launch your task, pull the container from ECR and your website will be accessible via your load balancer!
At this point, assuming your computer has the AWS CLI installed with the proper rights as well as Docker, you could do a deployment with the following commands:
$(aws ecr get-login --no-include-email --region your-region)
docker build -t image .
docker tag image:tag $AWS_ECR_REPOSITORY:tag
docker push $AWS_ECR_REPOSITORY:tag
aws ecs update-service --cluster YourCluster --service YourService --force-new-deployment --region your-region
This would work, but do you really want to to this every time you want to deploy your application? Nah, let’s automate it a bit more.
Configure Auto-Deployment with GitLab
This is the final piece of the architecture we are building. Wouldn’t it be nice if we could just deploy our application simply by merging a pull/merge request? This dream will come true in this paragraph!
We are going to build this using GitLab, but I am certain that the same thing could be done with GitHub actions or on BitBucket. This assumes that your GitLab instance contains a runner that supports Docker.
First, because we need to ship a complete Docker image to ECR, we need a way to include the credentials such as the database access to the image without versioning them. Fortunately, GitLab offers the perfect solution for this: the CI/CD environment variables.
Go to your repository’s Settings section, then CI/CD. Unfold the Variables section and you can input your passwords there. For example, this is where we will store the APP_KEY of our Laravel application.
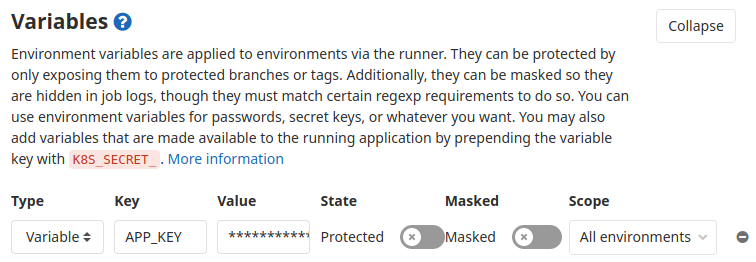 Repeat this for all the passwords you need to define in your application (database, etc). Note that if your password contains a $, because this is a special character, you need to double it ($$).
Repeat this for all the passwords you need to define in your application (database, etc). Note that if your password contains a $, because this is a special character, you need to double it ($$).
Next, in the case of our Laravel application, all the credentials are stored in a .env file. This is also the case for Symfony. From the .env.example file, let’s create a new .env file tailored for CI purposes, say .env.ci. Simply replace all the entries that need to be filled from the variables like this:
APP_KEY="${APP_KEY}"
To connect to the AWS CLI, create a IAM user with enough rights to access ECR and ECS, since we want to be able to push a Docker image to ECR and trigger an ECS deployment. You can create a CLI user and attach the following policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GitLabCI",
"Effect": "Allow",
"Action": [
"ecs:UpdateService",
"ecr:CompleteLayerUpload",
"ecr:TagResource",
"ecr:GetAuthorizationToken",
"ecr:UploadLayerPart",
"ecr:InitiateLayerUpload",
"ecr:BatchCheckLayerAvailability",
"ecr:PutImage"
],
"Resource": "*"
}
]
}
Note that you could (and should) create one user per project and even per environment and limit the resources your user can access to their environment. This is not done here for the sake of simplicity.
When the user is created, update the GitLab variables. Add the access key to the AWS_ACCESS_KEY_ID variable and the secret key to the AWS_SECRET_ACCESS_KEY variable.
Now that we have a shiny new CI-compatible .env file, let’s create the actual GitLab CI configuration file. Create a new file named gitlab-ci.yml at the root of the repository with the following content:
image: docker:19.03.1
variables:
AWS_ECR_REPOSITORY: 000000000000.dkr.ecr.region.amazonaws.com/repository-name
services:
- docker:19.03.1-dind
before_script:
- apk add --no-cache curl jq python py-pip gettext
- pip install awscli
stages:
- build
deploy to prod:
stage: build
script:
- envsubst < .env.ci > .env
- $(aws ecr get-login --no-include-email --region your-region)
- docker build -t image .
- docker tag image:tag $AWS_ECR_REPOSITORY:tag
- docker push $AWS_ECR_REPOSITORY:tag
- aws ecs update-service --cluster YourCluster --service YourService --force-new-deployment --region your-region
only:
- master
Replace the AWS_ECR_REPOSITORY URL by your ECR URL as well as YourCluster, YourService and your-region by the actual values. Additional information about GitLab CI and Docker in Docker is available here. Using a Docker image that runs Docker in Docker (dind), this script tells GitLab to:
- Create the real .env configuration file from the GitLab variables using envsubst
- Login to AWS CLI
- Build the Docker image from the Dockerfile we created above
- Tag the image
- Push the image to ECR
- Deploy it to the ECS cluster
This will be triggered whenever a commit is pushed to master. You can create as many blocks as you want for each branch you have, or trigger this action manually. The GitLab documentation covers those cases.
Because nothing is never perfect, here is a non exhaustive list of improvements that could be done:
- Integrating unit tests as part of the deployment process
- Making the container listen to HTTPS 443 instead of HTTP 80
- Tighter permissions in IAM
- Adding support for temporary environments, to test a feature for example
- Implementing an easy way to rollback the container to the previous version, maybe using Green/Blue deployments?
- Configuring auto-scaling of the cluster
- Integrating AWS Cloudwatch for the container logs
- … you tell me?
And that’s it! This long journey is finally over but we made it. I hope you enjoyed it, but even if you didn’t please let me know what you think 🙂